Inleiding
DigitalHQ is een SAAS omgeving, zijnde een cloud platform met cloud applicaties.
De ambitie voor effectieve applicatie beschikbaarheid. Omwille van de afhankelijkheden van de verschillende lagen om de SaaS omgeving aan te bieden, worden SLA’s of Service Level agreements gedefineerd waar de klant de kosten-baten afweging kan mee maken.
DigitalHQ standaarden
De DigitalHQ cloud architectuur is opgebouwd op basis van de laatste beste praktijken, om gekende risico’s zo goed mogelijk af te dekken.
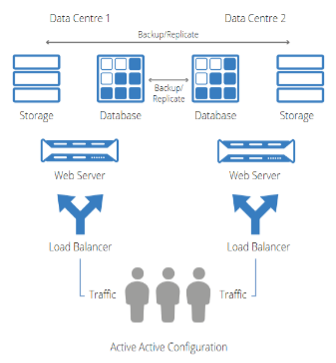
De server architectuur wordt steeds aangeboden in een active-active opstelling, waarbij de volledige opzet ontdubbeld wordt over 2 fysieke datacenters, die minstens op 15 km van elkaar verwijderd zijn en minstens 99,9% uptime garanderen.
Deze architectuur kan cloud hosted of dedicated hosted voorzien worden. Dedicated hosting voorziet een volledige oplossing in een Belgisch datacenter, hetgeen GDPR compliance future proof maakt. Cloud hosting is typisch goedkoper dan dedicated hosting.
DigitalHQ is een schaalbare SAAS omgeving. Zo wordt standaard elastische server architectuur gebruikt, die tot op zeker niveau automatisch opschaalt bij hoger gebruik dan voorzien. De kost hiervoor zit vervat in de onderhoudskost van de gebruikers.
Het database change log van DigitalHQ houdt alle aanpassingen aan databases bij, waardoor aanpassingen van een individu of vanaf een bepaald tijdstip kunnen teruggedraaid worden. Deze change log kan geconsulteerd worden in het kader van audits.
Disaster recovery wordt verzekerd volgens behoeftes betreffende Recovery Point Objectives (RPO) and Recovery Time Objectives (RTO). De kosten en baten van RPO & RTO objectieven bepalen uiteindelijk de recurrente kostprijs. Standaard wordt Bronze voorzien indien een klant een custom instance wenst te activeren in plaats van de SaaS omgeving.
Business continuiteit kan worden verzekerd aan de hand van een 3rd party SaaSEscrow opzet bij een externe leveranciers. Dergelijke opzet wordt standard op kwartaalbasis en bij elke release getest.
Voor Disaster Recovery en Business Continuiteit wordt gebruik gemaakt van 3de partijen die escrow services aanleveren. Deze worden als één geheel aangeboden, zowel de kost van de 3de partij als de interne kost om deze altijd up to date te houden.
|
|
Depot Source code |
Depot Data |
Ongestoorde continuiteit |
Bescherming waarden leverancier (IP, contracten, … ) |
|
|---|---|---|---|---|---|
|
Code Escrow |
2x |
- |
- |
- |
Incl. |
|
SaaS Escrow (incl 200 GB storage) |
2x |
V |
- |
- |
+ 6.500 € / jaar / 3rd party + storage kosten |
|
SaaS Secure |
2x |
- |
V |
- |
+9.500 € / jaar/ 3rd party + storage kosten backups |
|
SaaS Continuity Escrow |
2x |
V |
V |
V |
Op aanvraag |
Optioneel kan de volledige omgeving geaudit worden. Dit is reeds gebeurd op huidige versie van DigitalHQ. Het rapport kan aangeleverd worden. Een volledige audit kost ongeveer 80K€.
Escrow werking.
DigitalHQ levert depots (Broncode, Data, Beschrijving SaaS Infrastructuur) online aan in Secure Storage. Deze wordt door DigitalHQ benaderd via VPN en daarbinnen worden bestanden overgedragen. Alvorens depots worden ge-upload, worden ze door DigitalHQ geëncrypt. De encryptiesleutel wordt door DigitalHQ verstuurd naar de Begunstigde en NIET naar de Escrow leverancier. Hierdoor ontstaat er een situatie waarbij de Escrow een depot heeft waar zij niet zonder hulp van DigitalHQ bij kunnen. De Begunstigde heeft een sleutel maar kan niet bij het depot. Pas als depots moeten worden vrijgegeven, ontvangt de Begunstigde de benodigde credentials (password, user id) om in te loggen.
|
SLA niveaus |
Bronze |
Silver |
Gold |
Platinum |
|
Recovery Point Objectives (RPO) |
Iedere dag – End Of Day |
Iedere 4 uur[1] |
||
|
Recovery Time Objectives (RTO) |
Binnen 2 weken |
Binnen 1 week |
Binnen 48 uur |
Binnen 24 uur |
|
Reactietijden |
Volgende dag |
Zelfde dag |
4 uur |
2 uur |
|
Support priority |
|
|
V |
VV |
|
Data retentie |
60 dagen |
60 dagen |
180 dagen |
2 jaar |
|
Backup continuous snapshots |
iedere 4u |
iedere 4u |
iedere 4u |
iedere 4u |
|
Backup full - wekelijks |
optioneel |
optioneel |
optioneel |
optioneel |
|
Backup full - maandelijks |
2x |
2x |
6x |
12x |
|
Backup full – 6 maandelijks |
|
|
1x |
4x |
|
Data herstel |
RTO |
RTO |
RTO |
RTO |
|
SaaS Support |
V |
V |
V |
V |
|
Code deposit escrow |
2x 3rd party |
2x 3rd party |
2x 3rd party |
2x 3rd party |
|
SaaS Continuity |
Internal |
1x 3rd party |
internal + 1x 3rd party |
internal + 2x 3rd party |
|
Dual datacenter setup Active-Active Redundancy |
|
V |
V |
V |
|
Dual external monitoring |
|
V |
V |
V |
|
Pro-Active Services Security updates |
Quartely |
Quartely |
Monthly |
Weekly |
|
SAAS Escrow Copy of code, applications, virtual servers, deployment script, data |
|
|
V |
V |
|
Disaster Recovery Plan testing Quartely verification that replicated SaaS environment is operational |
|
|
V |
V |
|
SaaS Continuity Escrow Fully operational copy of servers, applications and data |
|
|
|
V |
|
Business Continuity Plan testing Quartely verification that replicated SaaS environment is operational |
|
|
|
V |
|
|
|
|
|
|
|
Kost per jaar incl hosting, incl 200 GB storage, incl verzekering |
40 K € / jaar |
85 K € / jaar |
125 K € / jaar |
195 K € / jaar |
|
Boete mechanisme bij SLA inbreuk[2] |
100 €/ uur |
200 €/ uur |
500 €/ uur |
1.500 € / uur |
1 Uren zijn steeds kantooruren
2 enkel voor kantooruren van toepassing tot maximaal 50% van maandelijkse kost voor SLA.
SLA Uitsluiting voor cyber incidenten, software van derde partijen en infrastructuur componenten
Recovery Time Objectives (RTO) zijn niet van toepassing bij cyber incidenten.
De SLA is niet toepasselijk op onbeschikbaarheid van software of hardware van 3de partijen.
SLA Carve-out voor crypto risico’s
Het grootste risico van IT omgeving op vandaag is de “menselijke fout” waarbij een bestand dat geïnfecteerd is met crypto-ransomware, geupload wordt door een gebruiker naar de applicatie en hierdoor langdurige onbeschikbaarheid zou creëeren. Organisaties dienen voor zichzelf te bepalen, wat de waarde is van de frequentie van backups alsook de noodzaak en het interactie niveau om terug live te zijn.
Recovery Time Objectives (RTO) worden bij een crypto event niet gegarandeerd, en er wordt in overleg bepaald welke backupversie terug online gezet wordt.
SLA Carve-out voor 3de partij software en infrastructuur componenten
De SLA is toepasselijk op onbeschikbaarheid van integratie en software van 3de partijen.
Ransomware mitigatie
Steeds vaker zien we alarmerende berichten rondom Ransomware. Organisaties die getroffen worden betalen honderdduizenden euro’s om weer bij hun eigen gegevens te kunnen. Wat is Ransomware en wat kun je er tegen doen?
Wat is het?
Ransom malware, of Ransomware, is een soort malware (kwaadaarige software) die ervoor zorgt dat gebruikers geen toegang krijgen tot hun systeem of bestanden. De bedenkers en verspreiders van de Ransomware eisen dan losgeld zodat u weer toegang tot uw eigen gegevens.
Hoe komt het op uw systeem?
Ransomware kan op verschillende manieren uw systeem besmetten: via mail spam, ongevraagde e-mail waarmee malware op uw computer wordt gezet. Deze e-mail bevat vaak een bijlage met een gevaarlijkste code die verstopt kan zijn in PDF- of Word-bestanden. Er kunnen ook links in zitten naar kwaadaardige websites. U kunt ook via kwaadaardige advertenties op valide websites worden omgeleid naar kwaadaardige websites die uw systeem besmetten.
Komt het vaak voor?
De cijfers liegen er helaas niet om. Eind 2020 was meer dan 35% van de bedrijven slachtoffer geworden van een aanval met ransomware.
Wat kan ik er tegen doen?
- Goede computerbeveiliging: er zijn goede programma’s verkrijgbaar die uw systemen realtime tegen malware aanvallen kunnen beschermen. Een goede netwerkbeveiliging in combinatie met goede detectie- en beschermingsprogrammatuur zijn een eerste vereiste. Daarnaast is het van belang dat u uw systemen en besturingssystemen regelmatig van beschikbare (veiligheids-) updates en patches voorziet.
- Gebruik het verstand: het klikken op bijlagen of links in onbekende emails (of emails die bedriegend echt lijken) is de belangrijkste bedreiging. Het bewust maken van mensen op deze risico’s en het leren omgaan met deze bedreigingen is een belangrijke maatregel.
- Maak regelmatig backups: Als u eenmaal besmet bent met Ransomware en u kunt niet meer bij uw gegevens, wat is er dan handiger dan een backup van uw gegevens op een veilige plaats? De meeste Ransomware is echter zo slim dat deze niet meteen actief wordt. Het duurt vaak enkele dagen tot weken (of nog langer) voordat de Ransomware actief wordt. In die tijd is de Ransomware mogelijk al meegenomen in uw backups en zijn uw backups na het terugzetten van uw schijnbaar veilige gegevens, ook niet meer bereikbaar. Het is daarom zaak regelmatig en langdurig backups te maken. Denk dan een dagelijkse backup in combinatie met een week backup, een maand backup en zelfs een kwartaal of jaar backup. Retentie (het lang genoeg vasthouden van voldoende versies) is essentieel om weer terug te kunnen naar een niet besmet systeem.
Onze standard praktijken voor maximale uptime zekerheid
| No single points of failure | => | redundancy for each layer |
| Scalability | => | resources to handle more users |
| Elasticity | => | automatic adaption to higher loads |
| Business continuity | => | how much issue is an issue? Next day is fine? |
| Disaster recovery | => | redundant infrastructure |
| Application security | => | VPN setup for each user |
| Resource monitoring | => | multiple monitoring solutions |
| Latency | => | local computing can reduce latency |
| DDOS mitigation | => | optional: CDN (content delivery network) |
| Business continuity and disaster recovery (BCDR) planning & regular testing | ||
| Pré-payment of hosting | => | up to 1 year upfront |
Active-Active Dual datacenter setup
Platinum Application security

Potential reasons for downtime and mitigation processes.
- Security events – acces control
- Security is paramount – eliminate external threats with encryption
- VPN tunnel activation per client, no online accessibility
- HTTPS protocols
- Multi-factor authentication login via QRcode with authorized app
- Encryption on databases (Amazon S3 & Azure Blob storage)
- Hacking of cloud consoles to manage AWS / AZURE / …
- Offline escrowed snapshots of data, code and virtual servers
- Automated deployment of old setup with the touch of a button
- Instance failures
- If an instance fails, it can take some time to restart. However, multiple instances can stop working if dependencies are lost and don’t recover after restart.
- Elastic instances are possible, yet costly and difficult to set up
- Application failures
- Software failures can happen, commonly related to unexpected user input and management of system resources.
- If 90% of the application functions correctly, then the system is considered up & running
- Previous version will still remain up & running
- Integration failures
- Integrated software components can malfunction due to bugs or updates.
- No liability is accepted on behalf of third-party software components, as we are only integrating them.
- Automated compliance controls
- Cloud services such as AWS Inspector, AWS CloudWatch, AWS CloudTrail, and AWS Config automate compliance controls.
- Identifying downtime
- Downtime must be reported to the ticketing system, triggering several processes for “automated remedying.”
- Automated remedying
- 24/7 support
- Impossible to guarantee 99+% uptime without on-call support personnel
- Cheapest option allows for a maximum of 48 hours of downtime.
- Permanent maintenance tasks
- Regular Security Updates – To protect from malicious users taking down systems.
- Redundancy – To take over when failures are detected.
- Data backup and recovery – To restore data to the last good condition in the event of a failure.
- Business continuity and disaster recovery testing
- Risk Assessments – To identify new risks from functionality, technology, or security trends.